Find Element Strategies
Find Element Strategies
Context:
Before we perform any operations like click, set text etc. on web elements, we will need to identify the element on the web page. As we mentioned before, “identifying” means identifying it in the DOM and being able to specify our search criteria for the element so that we can find a unique match.
The search criteria is generally referred to as selector/locator. The selectors can be any(or multiple) of the following:
- id
- name
- class
- linkText
- partiallinkText
- tagName
- custom attribute
- xpath
- css
Pre-requisites:
- You have completed the section “Set up Env” and have your environment ready with JDK, maven and Eclipse (+plugins)
- You have read and understood HTML DOM
- You were able to comprehend “Browser Commands” post
- You downloaded the project code base for class2 under – https://github.com/machzqcq/CucumberJVMExamples and imported into Eclipse and the structure should look as below
If you have Intellij [which I recommend over Eclipse], then imported project should look something like this.
Syntax:
OR
- Every HTML element in Selenium Java is of type “WebElement”
- A WebElement can be compared to an in-memory (DOM) object representation of HTML tag
- If the reference of driver is of type “Webdriver”, then we use the second syntax style, otherwise the first style. Both the styles work fine.
- To identify a tag (aka. web element) we might need any(multiple) of the following
- By.id
- By.name
- By.linkText
- By.partialLinkText
- By.className
- By.CssSelector
- By.tagName
- By.xpath
Selector/Locator:
Lets hit the website “http://www.practiceselenium.com/practice-form.html” . And right click on “firstname” text box and inspect element in Chrome browser.
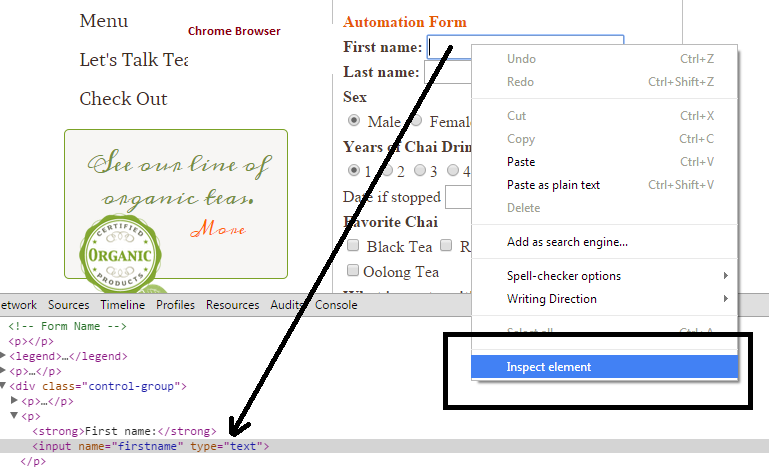
- We can see the HTML representation of the text field “firstname”.
- It has attributes name=firstname and type=text
- We will use By.name(“firstname”) to identify this element in Selenium
- This is the strategy we will follow to identify elements. If there are multiple attributes, then the order of preference can be id < name < class < tagName < className < cssSelector < xpath [We did not mention linkText because it applies only to a link and not all Web Elements]
- With this background, lets identify different HTML elements on this page and print its html.
By Name
By id
By linkText
By className
Retrieve HTML of WebElement
To retrieve the HTML of WebElement we print the attribute “outerHTML” for the element.
To retrieve attributes, we use the method “getAttribute” on the WebElement. We will discuss all the options in the training class, but for now, this should give you enough idea how to retrieve different values out of a HTML tag [aka. WebElement in Selenium language]
Let’s try to identify all elements on the above practiceselenium website and print its html.
The steps are the same as described in the videos and description on “Browser Commands”
- Download and import the maven project into Eclipse – https://github.com/machzqcq/CucumberJVMExamples
- How to download and import has been explained in detail in “Browser Commands” page video at the bottom
- There are two features “WebElements.feature” and “HtmlLocators.feature”
- Their corresponding step_definitions are in the files “WebElements.java” and “HtmlLocators.java” [Mapping 1-1 feature to step definition is not a good practice as per cucumber, but for now our focus is to learn selenium java api first, so we can refactor this code later]
Cucumber Features
WebElements.feature
HtmlLocators.feature
Corresponding step_definitions
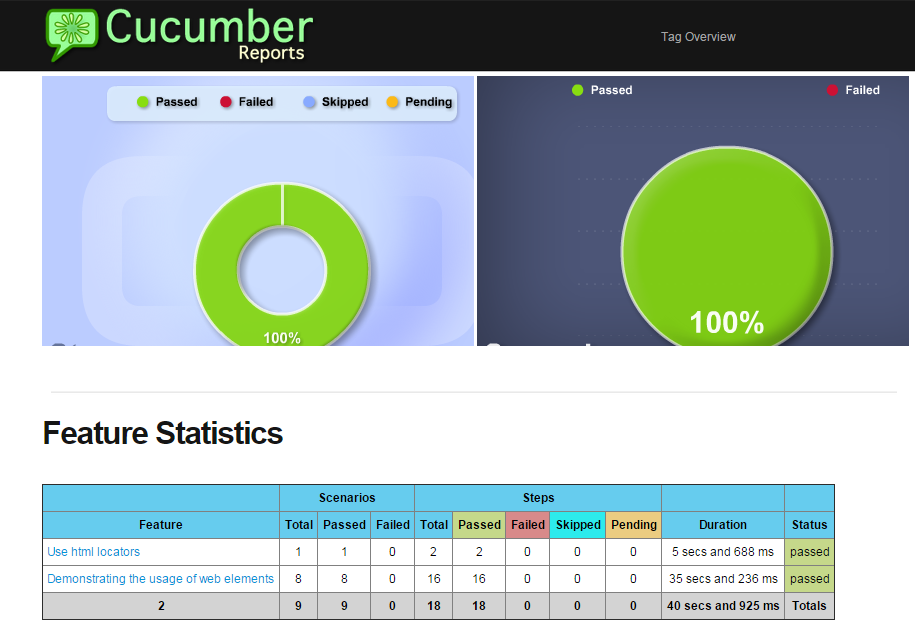
Execution Output
Intellij execution output (How to execute explained in previous post)
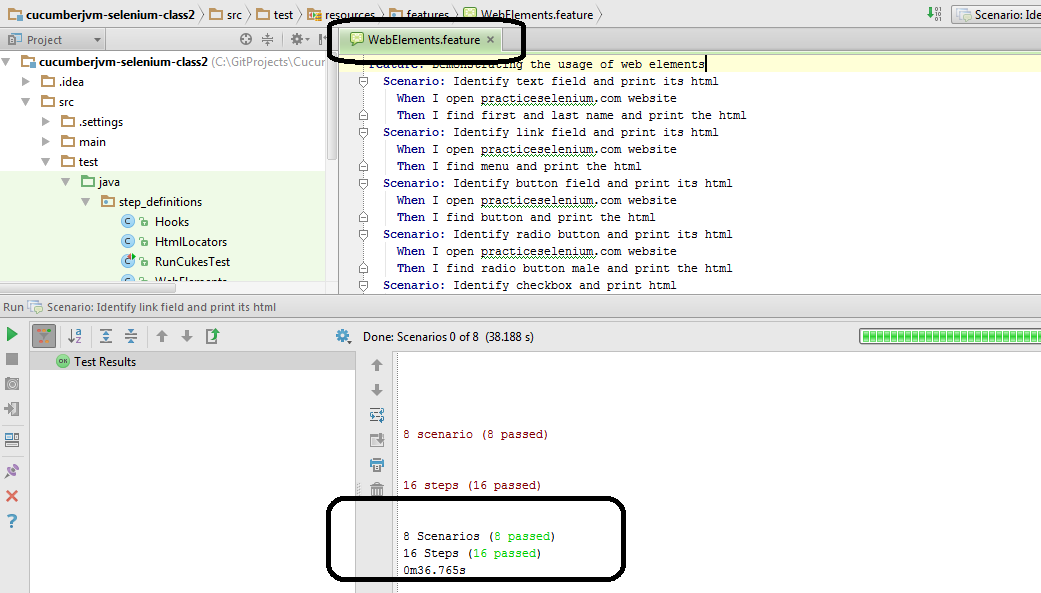
If you executed WebElements.feature from eclipse plugin, then it should look similar to the below
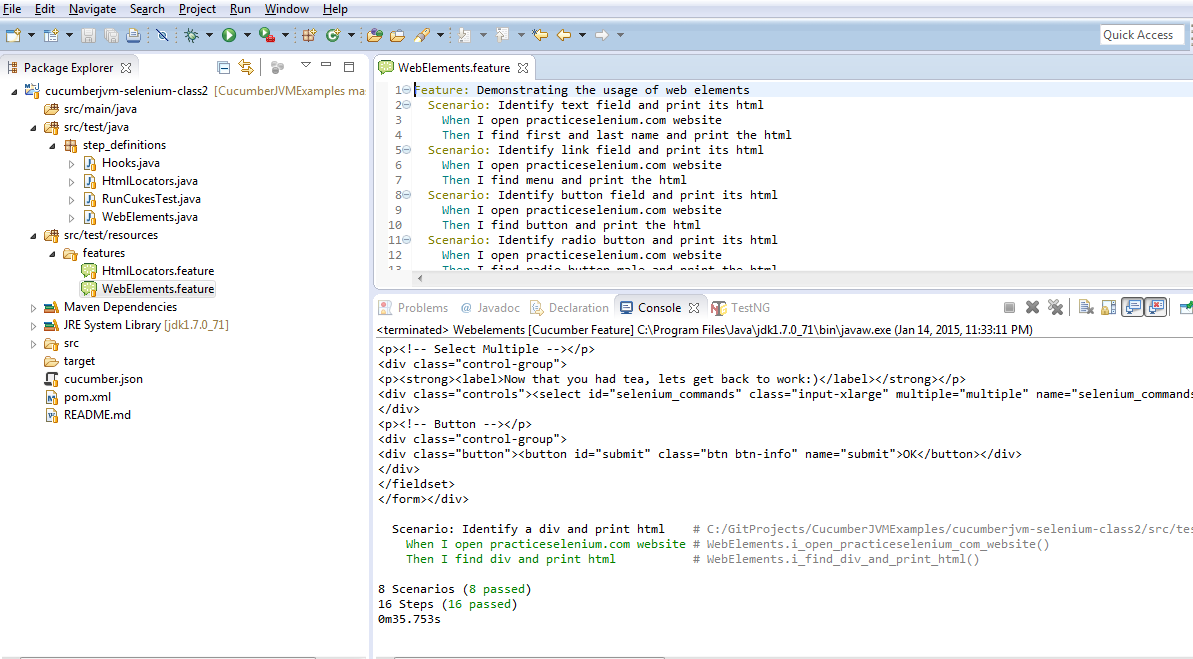
Eclipse Execution
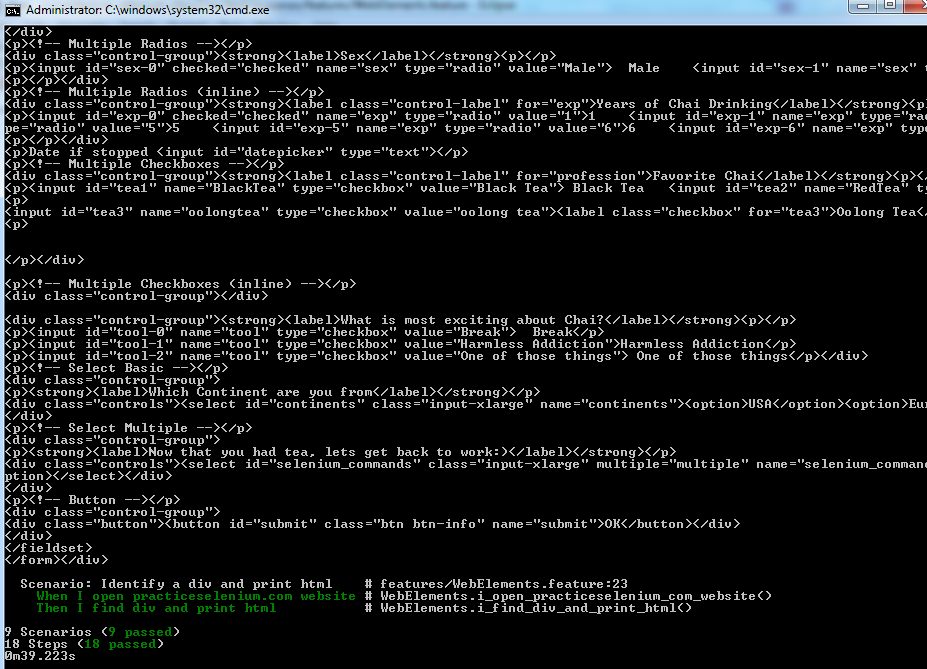
Command line execution
If you executed “mvn test” from command line, then the output should be 9 scenarios pass, since all .feature files get executed.
CI Server